
Datenarchitekturen für Business Intelligence Systeme
Ausgehend von der Definition des Data Warehouse nach William H. Inmon[1] wird zunächst der Hub-and-Spoke-Ansatz als grundlegende Architektur im Data Warehouse-Umfeld vorgestellt. Darauf aufbauend werden die verschiedenen Interpretationen der Grundarchitektur und die maßgeblichen Konzepte des „Enterprise Data Warehouse“¹, des „Dimensional Data Warehouse“[2] und des „Data Vault-Ansatzes“[3] gezeigt. Abschließend wird der Data Vault tiefgreifend erläutert.
Core Data Warehouse mit Hub-and-Spoke-Architektur
Die wahrscheinlich bekannteste Definition eines Data Warehouse nahm William H. Inmon im Jahr 1992 in „Building The Data Warehouse“ vor. Inmon definiert das Data Warehouse wie folgt:
„A data warehouse is a subject-oriented, integrated, time-variant, nonvolatile collection of data in support of management’s decision-making process.” ¹
Um eine Data Warehouse Datenbank zu realisieren, welche den oben genannten Ansprüchen gerecht wird, entwickelten sich verschiedene Architektur- und Modellierungskonzepte. Grundlegende Gemeinsamkeit der in diesem Papier betrachteten Konzepte ist die Hub-and-Spoke-Architektur, welche in der folgenden Abbildung dargestellt ist:
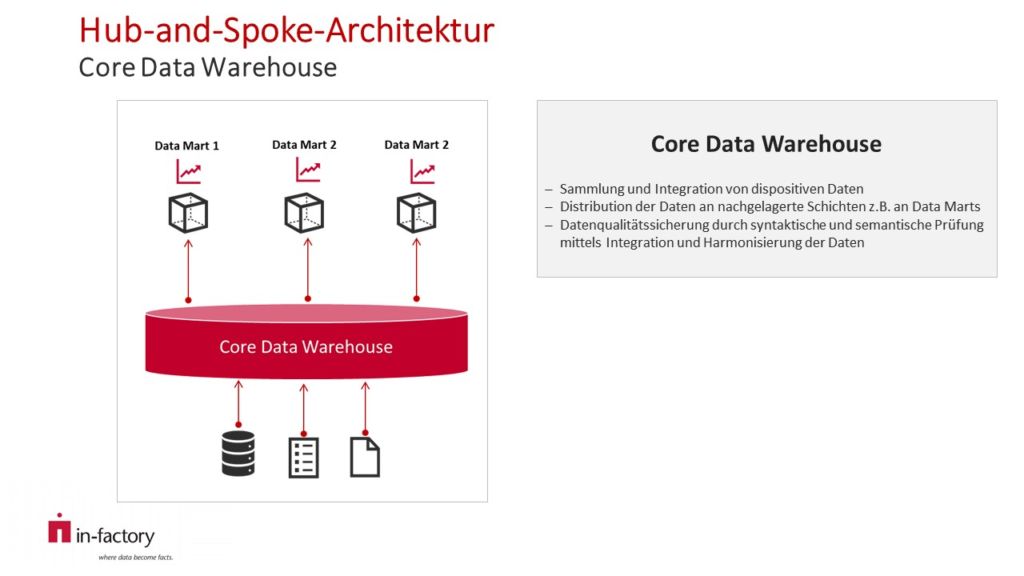
Hub-and-Spoke-Architektur
Das Core Data Warehouse dient als „Hub“ und erfüllt die Aufgabe der Integration, Qualitätssicherung und der Datenverteilung an die Data Marts. Die Data Marts sind die „Spokes“ und weisen eine Anwendungsorientierung, sowie vordefinierte, betriebswirtschaftliche Anreicherungen und Aggregation auf.
Überblick zu den Datenarchitekturen
Die wesentlichen Architekturen im Data Warehouse-Umfeld basieren auf dem oben erläuterten Hub-and-Spoke-Ansatz:
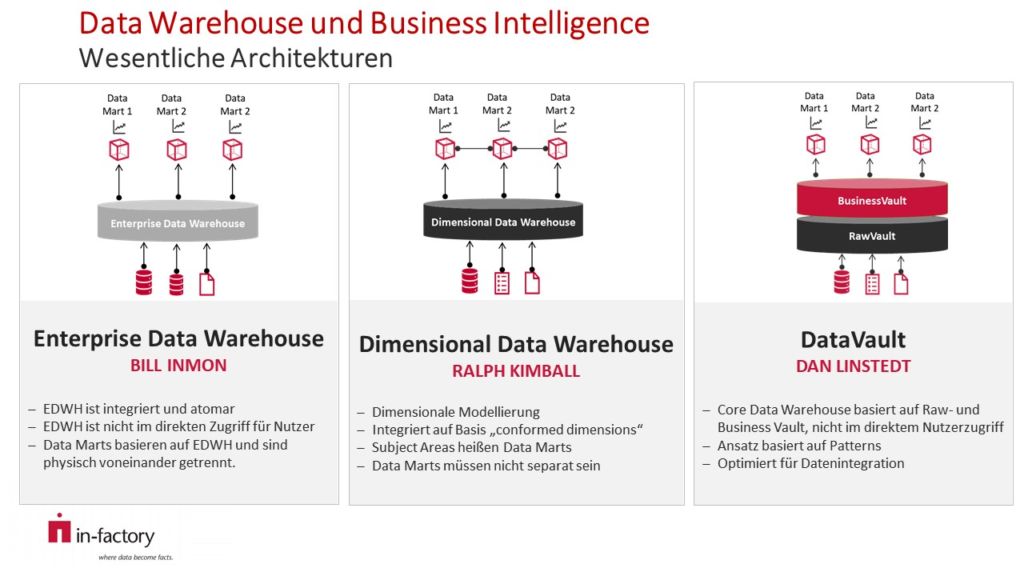
Wesentliche Architekturen im Data Warehouse-Umfeld
Das Core Data Warehouse integriert die Daten und populiert die Data Marts, welche als Grundlage für Datenanalyse und Reporting agieren.
- Enterprise Data Warehouse: Ziel des Architekturvorschlags von Inmon ist es, ein unternehmensweites Datenmodell für das Core Datawarehouse zu erstellen. Die Daten sind in der dritten Normalform (3NF) organisiert und liegen atomar vor. Aus diesem Datenpool lassen sich die Data Marts leicht aufbauen. Kennzahlendefinitionen gelten über das gesamte Modell. Im Ergebnis entsteht ein komplexes Modell mit einer Vielzahl von Tabellen und Beziehungen. Die Weiterentwicklung und Pflege des Systems sind daher aufwändig.
- Dimensional Data Warehouse: Kimball sieht für das Core Data Warehouse ein dimensionales Datenmodell in Star-Schema-Modellierung vor, d.h. die Daten werden in Dimensions- und Faktentabellen vorgehalten. „Confirmed Dimensions“ lassen sich Use-Case übergreifend mit verschieden Faktentabellen, also in verschiedenen Businesskontexten, nutzen. Änderungen an den Quellen führen in der Regel zu aufwändigen Entwicklungstätigkeiten. Der dimensionale Modellierungsaspekt wird häufig auch in anderen Architekturansätzen auf Ebene der Data Marts eingesetzt.
- Data Vault-Ansatz: Linstedt entwickelte die grundsätzliche Architektur weiter und adressiert im Data Vault-Ansatz nicht nur Datenmodellierungsaspekte, sondern schlägt auch geeignete Vorgehensmodelle vor. Durch die Verwendung von nur wenigen Modellierungsmustern resultiert eine hohe Flexibilität gegenüber Änderungen. Die Data Vault-Methode ermöglicht daher die von Fachabteilungen häufig geforderte Agilität und vereinfacht die Anpassung der Business Intelligence-Lösungen aufgrund veränderter Anforderungen.
Grundsätze der Architektur des Data Vault
Die unten dargestellt Grundarchitektur mit Raw Vault und Business Vault folgt dem Hub-and-Spoke-Ansatz.
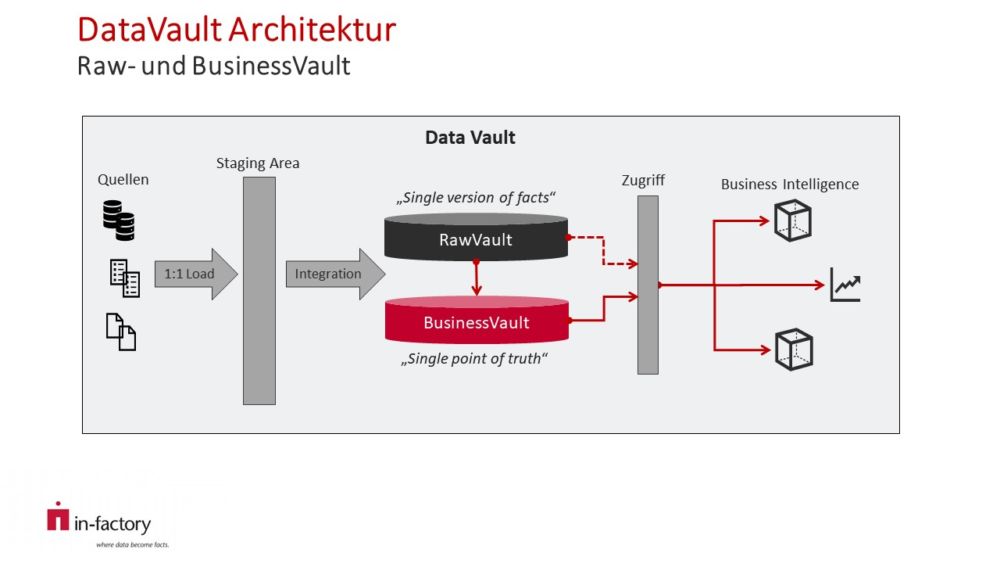
Grundarchitektur mit Raw Vault und Business Vault
Der Raw Vault nimmt die Daten der Stage Area auf. Dabei werden Beziehungen zwischen Objekten identifiziert und die beschreibenden Attribute historisiert gespeichert. So entsteht die „Single version of facts.“. Nach Anwendung von Business-Logik (z.B. Aggregation und Transformation) stellt der Business Vault den „Single point of truth.“ dar. Der Zugriff des BI-Layers erfolgt über eine Zugriffsschicht, welche die Daten aus dem Business Vault bereitstellt. Spezielle Datenanforderungen können von der Zugriffsschicht auch durch den Raw Vault bedient werden.
Die verschiedenen Schichten der Architektur lassen sich wie folgt weiter erläutern:
Staging Area
Wesentliche Aufgabe der Staging Area ist es, die angelieferten Daten in inhaltlich unveränderter und dennoch optimierter Form für den Ladeprozess bereitzustellen. Diese Optimierung kann sich in einer relationalen Struktur auf dem Zielsystem manifestieren, um Medienbrüche und Network Traffic zu vermeiden bzw. zu minimieren. Möglich ist aber auch eine Landing Zone auf Ebene des Filesystems (Kriterium: Erreichbarkeit durch ETL-Server).
Die Datenstrukturen einer relationalen Staging Area bilden die Quellen ab. Hierbei wird bewusst weitgehend auf die Verwendung von Maßnahmen zur Sicherung der Integrität und inhaltliche Transformationen verzichtet. Wichtig sind allein Geschwindigkeit und Funktionssicherheit des Ladeprozesses. So können im Sinne des agilen Ansatzes neue Quellen zügig angebunden werden. Bestehende Quellen können parallel bewirtschaftet werden und die Reorganisation der Daten kann flexibel implementiert werden.
Raw Vault
Die Daten bleiben im Raw Vault weiterhin inhaltlich unverändert. Die Aufgabe des Raw Vaults ist vielmehr die Integration und Historisierung der Information.
Die Daten werden also Businessobjekten zugewiesen, die wiederum als Hubs und Satellites bzw. Links und Satellites definiert sind. Hubs enthalten Schlüssel zur eindeutigen Identifikation einer Entität, zugehörige Satellites enthalten die beschreibende Information und leisten die notwendige Historisierung. Links verbinden Hubs und haben eigene Satellites zur Beschreibung der Relation. Innerhalb dieser Strukturen werden die Informationen den Zieldatentypen zugeordnet. Referenzen in eine relationale Staging können temporär Lineage-Funktionalitäten ermöglichen.
Alle Tabellen im Raw Vault werden dabei mittels gleichförmigen „Insert Only“- Prozessen bewirtschaftet (unterschiedliche Hashwert-Vergleiche je nach Zieltyp) und sind einheitlich strukturiert. Die bewirtschaftenden Prozesse eignen sich daher besonders für die Automatisierung.
Business Vault
Der Business Vault wird im Anschluss an den Raw Vault bewirtschaftet und befindet sich im gleichen Schema. Seine Aufgabe ist die Abbildung der Business Rules, welche die Geschäftsanforderungen abbilden und die Daten inhaltlich verändern. Aus belieferten Kennzahlen im Raw Vault werden KPIs abgeleitet. Aggregation und Konsolidierung von Daten aus unterschiedlichen Systemen werden vorgenommen.
Zugriffsschicht
Gegebenenfalls auch virtuell aufgebaut ist die Zugriffsschicht, die auf Daten des Business- und eventuell des Raw Vault zugreift. Sie folgt den Erfordernissen der eingesetzten BI-Infrastruktur, weist regelmäßig dimensionale Züge auf und ist nach Use Cases organisiert.
Einzelne Use Cases (dies betrifft erfahrungsgemäß das eher atomare Berichtswesen, Legal Reporting oder Exporte) können auch direkt auf das Business Vault bzw. das Raw Vault durchgreifen.
Im Blogeintrag „Data Vault Grundlagen“ wird näher auf die Architektur eines DV eingegangen und anhand eines Use Cases veranschaulicht.
[1] Building the Data Warehouse (1992)[2] The Data Warehouse Toolkit 3rd Edition (2013)[3] Data Vault Series 1 – Data Vault Overview (2002)