
One of our customers in the automotive sector had a requirement to implement a full-text search on a relational Oracle database. Various hits, weighted according to so-called "scores", were to be delivered as results.
The existing system is an Oracle DB (DataVault architecture). A complete contact data record therefore requires a join across several tables.
On the one hand, Oracle's on-board tools were considered as possible technologies for use and, on the other hand, alternative solutions were also evaluated. As the customer places a strong focus on Free and Open Source Software (FOSS) components, the Opensearch suite was selected for the implementation of this requirement.
Overview Opensearch
Opensearch is a distributed open source search and analytics suite that provides a highly scalable, highly available system for fast access to large amounts of data. Opensearch is based on the Apache Lucene search library and is a branch of Elasticsearch 7.10.2.
Opensearch was further developed as a fork of the last ALv2 version (Apache License version 2) of Elasticsearch after the licensing strategy of Elastic NV was changed.
The Opensearch Suite essentially consists of three components:
- Logstash, an ETL tool, is used to import data.
- Opensearch analyzes/indexes/stores the data and provides the actual search engine.
- Opensearch dashboard provides visualization and management tools.
Project implementation
System architecture
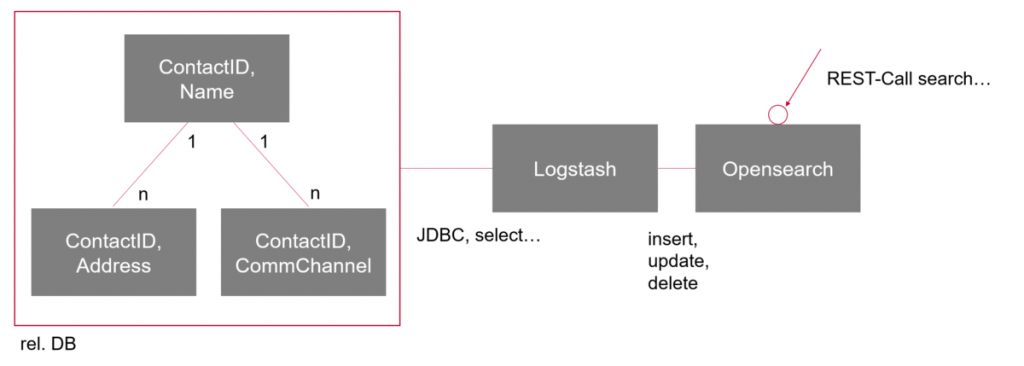
The requirements were implemented as follows:
- Logstash regularly imports all or new contacts via JDBC (Java Database Connectivity) via Oracle-Select to the relational (rel.) DB. Using a persistence marker, Logstash remembers up to "where" this job has already been done, so that only deltas are taken into account after the initial load.
- Individual fields can be manipulated and filtered within the Logstash pipeline.
- The Logstash export transfers the data to Opensearch, which "indexes" it and provides the REST (Representational State Transfer) web service endpoint of the search engine.
Special features
The following special features must be observed:
- Analysis and preparation of the data to be indexed and the search query: If you search for MuelLeR, for example, you expect "müller", "Müller", "mueller", etc. This can be achieved in Opensearch using country-specific indices to which different templates with different analysis tools are applied. These break down the data into individual terms, umlauts are standardized, the use of synonyms is enabled, "stemming" is carried out ("ging" is converted into "gehen", for example, so that you can search for all inflected forms of "gehen").
- Up-to-dateness of the index: If you delete contacts in the relational DB, they can still be found in the Opensearch search index. This means that you may need different Logstash pipelines that take care of the insert and delete use cases. The aim is of course for the search index to contain an up-to-date image of the relational database.