
In our "BigData" project at an automotive manufacturer, deployment became an increasingly important aspect of software development. Due to the increased scope of the packages and the diverse environments, combined with the requirement to be able to set up an environment from scratch in one day, a SCRUM story "Deployment 2.0" was created.
What has the deployment process looked like so far?
The project includes various technologies that were large areas:
- Oracle database
- Informatica Workflows (IICS)
- Shell scripts for control and e.g. address validation
- APEX as Oracle GUI
- The scheduling software Control-M
The individual components were previously deployed using a shell script, as this is a Unix environment. This means that the configuration took place in a control file and the start script had to be started manually at the start time and the execution monitored live.
This was error-prone and also very limited in terms of parallel execution. Troubleshooting was also difficult. But above all, the process could only be monitored by one person on one computer.
Our solution approach
With the changeover of the scheduling software from Control-M to Automic (UC4), the idea arose to automate the entire deployment process at the same time and to adapt it to the new requirements (e.g. GIT as a versioning tool).
The packages did not have to be created and adapted manually after each development step; the sprint deployment (keyword SCRUM) was to be controlled entirely via tags.
Monitoring should be executable by several people and notification of errors should also be automatic.
Our implementation
First, the job net was roughly divided up on the drawing board as a template. In the following image, which represents the final version of the complete implementation of the deployment, you can see the breakdown of the respective steps.
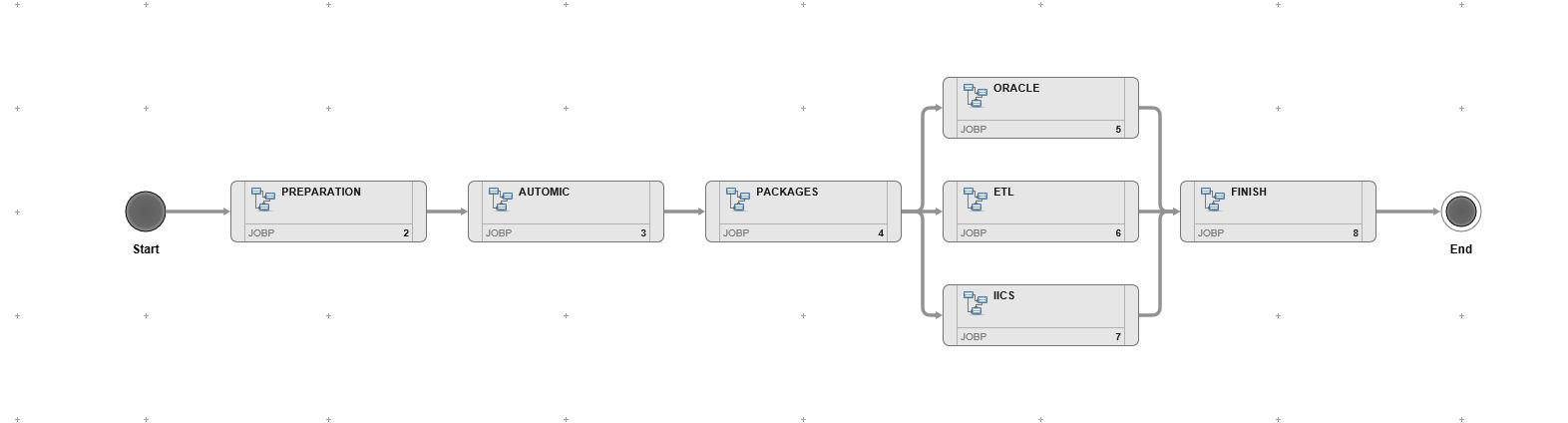
First, a script was written to handle the control of the respective packages to be rolled out, the "Preparation" group in the image. The GIT API was used for this, which provides exactly such scenarios and handles the respective steps. This made it possible to build packages in sprints and deploy them repeatedly. In addition, all information relevant to the respective deployment was collected.
Secondly, the update of the job networks was scheduled, group "Automic" in the image. With the information now available, the packages were extracted from GIT and divided up for each of the upcoming technology strands ("Packages" group in the image). The packages were each scheduled for parallel execution. This not only saved time, but also ensured that in the event of an error, it was not necessary to repeat the entire deployment, but only the faulty part.
In the last group "Finish", the environments were cleaned up, the logs were moved to the respective archive and the deployment was marked as successful in the database. Control was not via files, but via a table created for this purpose in the project database. This meant that the information could also be extracted and displayed in a GUI - for a quick overview of the respective environments (DEV / TEST / PROD) with the corresponding software versions and other desired information.
